
[Shell , Merge , Quick Sort]
4. 쉘 정렬 (Shell Sort)
: 요소간의 특정 간격 ‘k’에 해당하는 요소들을 하나의 부분 리스트로 하고 이를 삽입 정렬을 사용하여 정렬한다. ‘k’ 값을 1까지 줄여가며 이를 반복하여 정렬하는 방법
쉘 정렬은 ‘도날드 쉘’이 제안한 정렬로 삽입 정렬이 어느 정도 정렬된 배열에 대해서는 처리 속도가 빠르다는 것에 착안 하여 만들어 졌다. 기존 삽입 정렬의 문제점인 “요소들간의 교환(swap)이 이웃한 것끼리만 일어난다.” 라는 것을 개선하여 쉘 정렬은 요소들이 멀리 떨어진 위치로도 한번에 이동 가능 하다.
쉘 정렬은 특정 간격 ‘k’의 요소들을 가진 부분 리스트를 삽입 정렬하고 이 ‘k’ 값을 1까지 줄여가는 방법으로 정렬한다.
우리가 쉘 정렬을 사용하여 정렬 하고자 하는 원본 배열은 다음과 같다.

i ) 간격(gap) k가 5 일 때

① : 간격 k가 5이므로 인덱스 0, 5, 10의 데이터가 하나의 부분 리스트를 이룬다. (이 부분 리스트를 <부분 리스트 1>로 칭한다.)
② : <부분 리스트 1>을 삽입 정렬을 이용하여서 오름차순으로 정렬 하였다. [4, 8, 9]
각각의 5개의 부분 리스트에서 정렬된 요소들을 모두 합쳐주면 표 가장 하단의 “정렬 배열”과 같은 배열이 된다.
※ k=5 => 큰 인덱스 - 작은 인덱스 = 간격(gap) = k
ii ) 간격(gap) k가 3 일 때
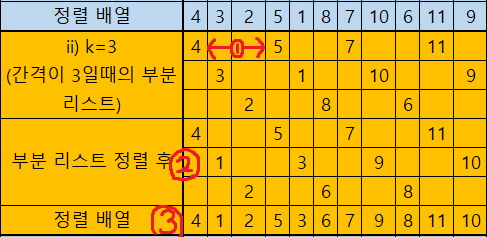
① : k가 3인 인덱스 0 ,3, 6, 9의 데이터가 하나의 부분 리스트를 이룸 => <부분 리스트 6> [3, 1, 10, 9]
② : <부분 리스트 6>을 삽입 정렬을 이용하여서 오름차순으로 정렬 => [1, 3, 9, 10]
③ : 부분 리스트 들을 합쳐서 배열을 합쳐서 정렬
iii ) 간격(gap) k가 1 일 때

크기가 1인 부분 리스트 들을 삽입 정렬을 통해서 정렬한다.
쉘 정렬의 전과정은 다음과 같다.

쉘 정렬의 장점 (삽입 정렬에 비해서)
1. 삽입 정렬은 연속된 요소간의 교환(swap)만 일어난다. 그러나 쉘 정렬의 부분 리스트는 간격(gap) k의 값에 따라서 더 큰거리를 이동할 수 있고 이 과정을 반복하면 최종적으로 정렬된 리스트와 빠르게 가까워질 수 있다.
2. k=5, 3인 경우를 거치면서 배열은 어느정도 정렬된 상태이다. 이 상태에서 k=1인 삽입 정렬을 한다면 어느 정도 정렬된 배열에서는 대단히 빠른 속도를 보여주는 삽입정렬이 정렬을 빠르게 수행 한다.
5. 합병 정렬 (Merge Sort)
: 정렬 하고자 하는 리스트를 정렬하기 편한 조각으로 나누어 (균등한 크기로) 조각을 각각 정렬한 뒤 결합하는 정렬 방법
합병 정렬 (merge sort)은 분할 정복 (Divide and Conquer) 기법을 바탕으로 한다.
* 분할 정복 기법 : 문제를 작은 2개의 문제로 분할하고 각각 해결한 뒤, 이를 모아 원래 해결하고자 하는 문제를 해결하는 방법
합병 정렬의 실행 과정
①분할 (Divide) : 배열을 2개로 나눔 (크기는 균등)
②정복 (Conquer) : 2개를 각각 정렬 (분할된 배열이 아직도 크면 순환 호출을 이용하여 다시 분할)
③결합 (Conbine) : 2개의 정렬된 배열을 결합

배열 [80, 40, 60, 30, 50, 20, 10, 70]을 합병 정렬로 정렬

배열 [30, 40, 60, 80]과 배열 [10, 20, 50, 70]을 합병하는 과정 => @ 과정

각 배열에서의 가장 작은 데이터 부터 차례대로 비교하여 정렬한다.

① : 왼쪽 배열에서 가장 작은 데이터인 “30”과 오른쪽 배열에서 가장 작은 데이터인 “10”을 비교
30 > 10 => 두 배열의 모든 데이터 중 가장 작은 데이터는 10

② : 왼쪽 배열에서 가장 작은 데이터인 “30”과 오른쪽에서 그 다음으로 작은 데이터 “20”을 비교
30 > 20 => 두 번째로 작은 데이터 20

③ : 30 < 50 => 배열에 30 입력 (index 2)

④ : 40 < 50 => 배열에 40 입력 (index 3)

⑤ : 60 > 50 => 배열에 50 입력 (index 4)
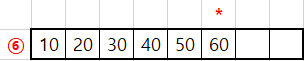
⑥ : 60 < 70 => 배열에 60 입력 (index 5)

⑦ : 80 > 70 => 배열에 더 작은 70 입력 (index 6) 후 80 입력 (index 7)
이러한 과정을 거쳐서 두 개의 배열이 합하였다.
6. 퀵 정렬 (Quick Sort)
: 피벗을 기준으로 왼쪽은 작은 데이터, 오른쪽은 큰 데이터로 위치 시키는 방법을 반복하여 정렬한다.
합병 정렬과 마찬 가지로 퀵 정렬(Quick Sort)도 역시 분할 정복 (Divide and Conquer) 기법을 바탕으로 한다.
배열 [50, 80, 40, 60, 30, 90, 20, 10, 70]을 퀵 정렬을 통해서 정렬 하는 과정

① pivot = 50 : 50을 기준으로 작은 데이터, 큰 데이터 위치 이동
② pivot = 10, 90 : 50을 기준으로 왼쪽 / 오른쪽으로 나누어진 배열내에서 다시 10, 90을 각각 pivot으로 설정하고 위치 이동
③ pivot = 30, 70 : [40, 30, 20]에서 30을 피벗, [80, 60, 70]에서 70을 피벗으로 설정하고 위치 이동
이와 같은 방법으로 배열을 퀵 정렬을 통하여 정렬한다.
'Data structure' 카테고리의 다른 글
| [C언어로 쉽게 풀어쓴 자료구조] Chapter 2 순환 - 팩토리얼(순환,반복) / 거듭제곱(순환,반복) / 파보나치 수열(순환,반복) (0) | 2022.02.15 |
|---|---|
| 기수 정렬 (radix sort) (0) | 2021.07.18 |
| 힙 / 힙 정렬 (Heap / Heap Sort) (0) | 2021.07.17 |
| 정렬 1 (Sorting) (0) | 2021.07.10 |
| 배열 (Array) (0) | 2021.07.09 |